
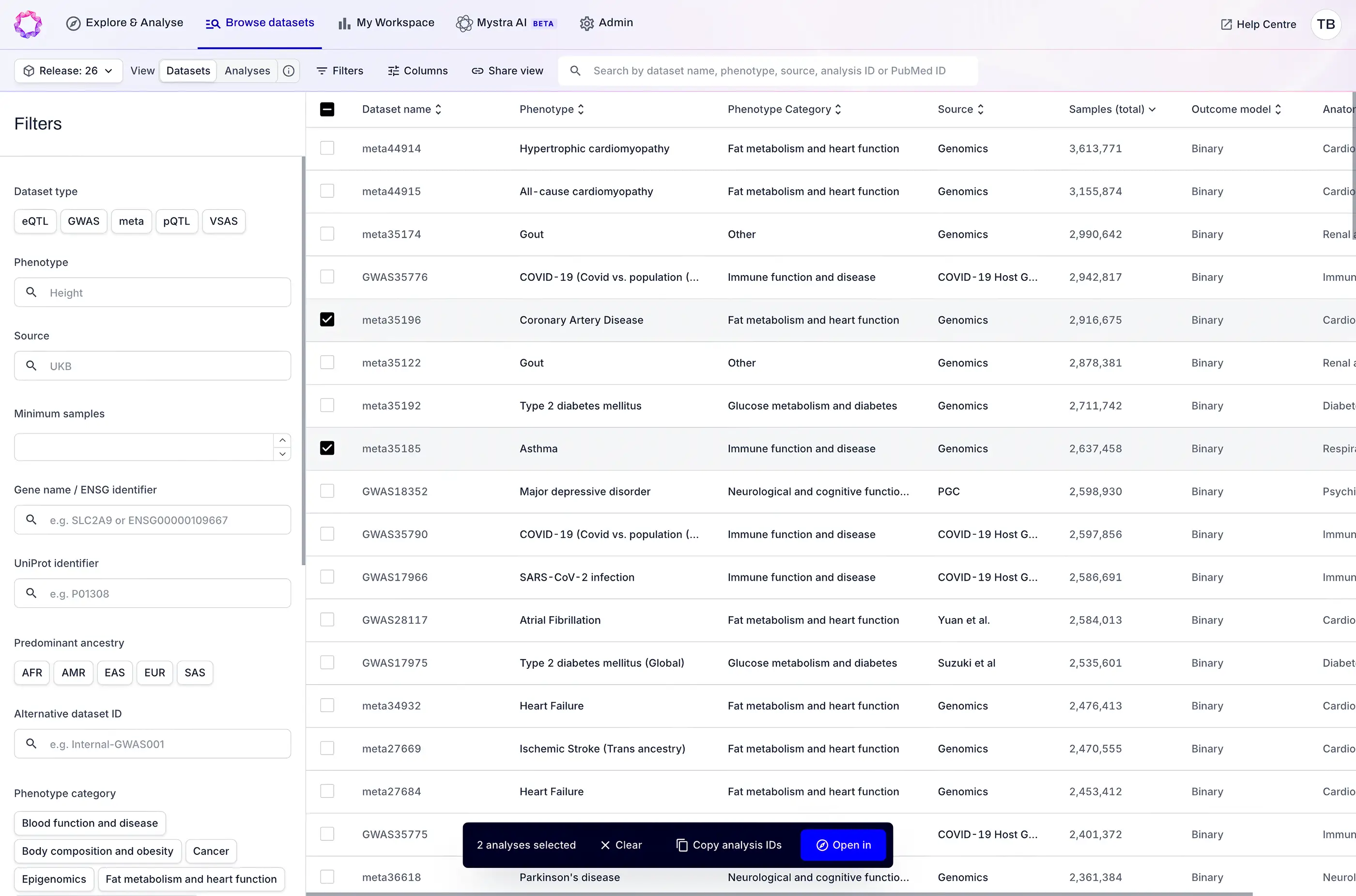
The platform provides scientists with full control and transparency of the R&D drug target discovery and validation process using genetic insights.
Genetic teams are slowed by fragmented tools and siloed data
Genomic data are dispersed, poorly annotated, and heterogeneous and interrogating these data is time consuming and often leads to conflicting answers.
3 Deloitte, Unleash AI's potential (2024)
Fragmented data landscape
Teams juggle dozens of disconnected datasets, losing hours to harmonisation and version control before any analysis can begin.
Analyses that take months
Workflows like colocalisation and Mendelian randomisation require specialist bioinformatics support and significant development time – delaying decisions at the moments that matter most.
No shared source of truth
Genetics, biology, and clinical teams work from different snapshots of evidence, creating misaligned priorities, duplicated effort, and late-stage surprises.
"Targets with human genetic support are 2.6 times more likely to succeed. The imperative isn't to do more genetics — it's to do it faster, earlier, and with greater confidence."
Mystra’s dual solution


Data Layer
A data layer, harmonised and curated, that enables your pipeline and workflow.
Mystra is handling the data acquisition, curation, managing access to proprietary sources, harmonising these inputs and providing access to a powerful programmatic interface that integrates with your internal workflows.


Data Portal
A lightning fast data portal with built-in workflows that enables rapid interrogation of the data catalogue
This enables fast turn-around time for target discovery and validation questions, and is an “all-in-one” option.
A new era of genomic intelligence
An emerging way to bring together the programmatic and graphical interface, Mystra AI provides access to data, workflows, through a powerful chat interface. Answers from the agentic workflows are based on the Mystra data store, rather than a black box from the literature, and every answer is supported by visuals and insights from the Mystra platform, to avoid hallucinations and support scientists day-to-day.
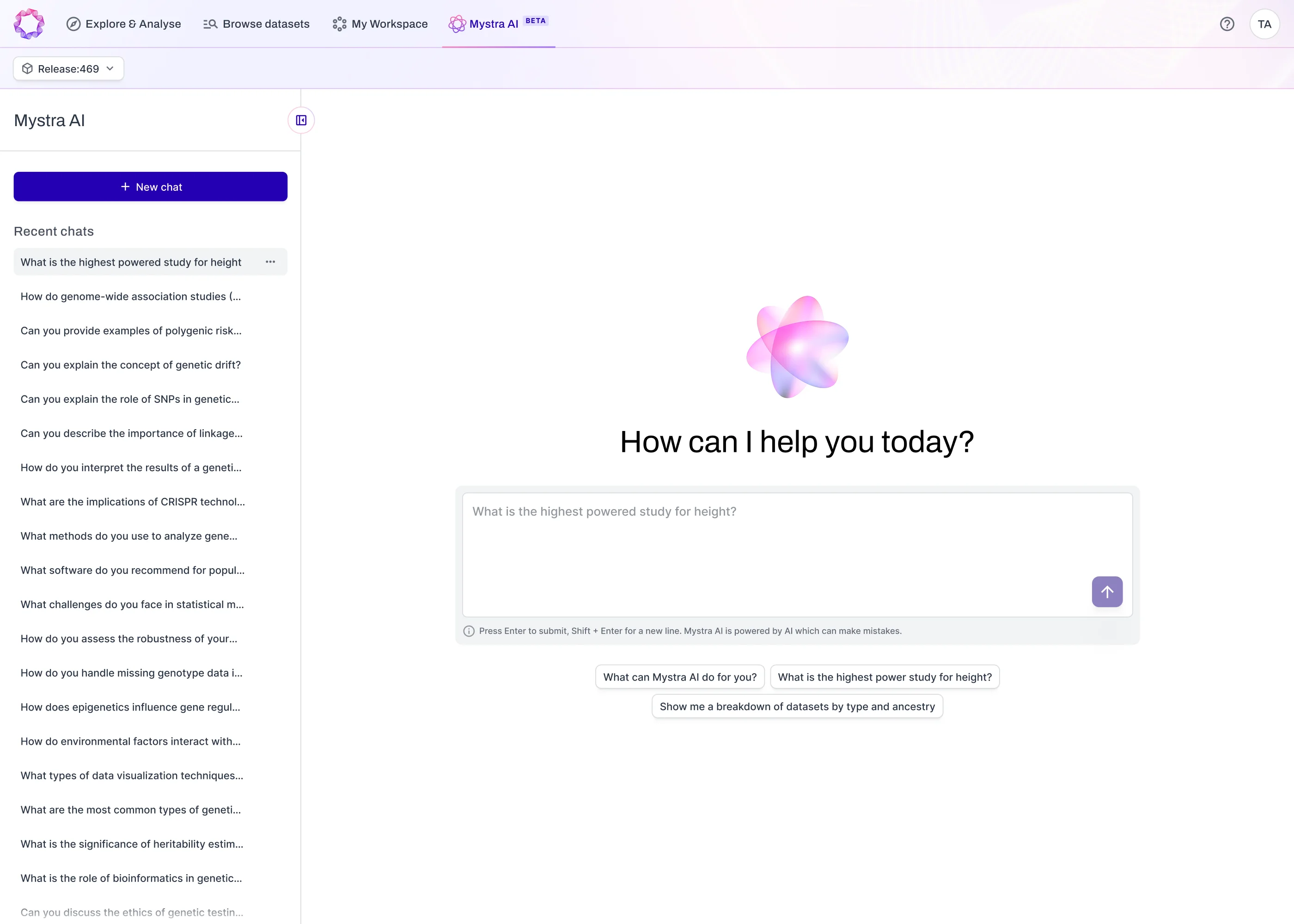
Target discovery
The assistant queries datasets, identifies tissue-specific eQTLs, presents results with sample sizes and effect directions, and suggests colocalisation with a relevant GWAS.
Colocalisation workflow
The assistant queries datasets, identifies tissue-specific eQTLs, presents results with sample sizes and effect directions, and suggests colocalisation with a relevant GWAS.
Complex loci investigation
Identifies relevant datasets, recommends conditional analysis to dissect independent signals, and proposes colocalisation as a follow-up step.

Powered by
Mystra and Mystra AI are built on top of a decade of genetic innovation by Genomics.
We’ve turned trillions of complex, raw global biobank data points into a single, harmonized, and deeply trusted reference engine.
Fully integrated into every Mystra workflow, this expert-curated dataset ensures your AI-driven discoveries are backed by the highest standard of statistical power and cross-ancestry precision.

“Drug targets with genetic backing are 2.6 times more likely to succeed in clinical trials. Mystra AI means greater ease of access and efficiency in generating powerful genetic insights to power drug target discovery.
All scientists in the Research & Development and Business Development & Licensing space will be able to harness the power of genetics to prevent, treat, and cure disease, whether identifying new targets for discovery, acquisition, or expanding indications for existing medicines - this means safer, more effective treatments for patients, faster.”

CEO and Co-Founder, Genomics
"We have built the largest human genetics dataset to deepen our understanding of human biology and diseases. By integrating this vast catalogue of human association data into an advanced AI platform, we are giving scientists worldwide the tools and data they need to discover the next generation of life-saving treatments"

President, Genomics
“Genomics has developed a transformational platform which will change the way diseases and targets are identified for the next generation of drug discovery.
In real time, you can do the work of an entire PhD in minutes.”

Chief Medical Officer, Amazon Web Services
“We are proud to be early adopters of Mystra AI. Genomics’ genotype-phenotype database supports our proprietary drug discovery efforts.
With Mystra AI, our R&D teams have been able to explore and evaluate biological insights efficiently and at pace.”

CEO, Relation Therapeutics
"The release and rapid adoption of Mystra AI demonstrates the UK's ability to harness and use genomic data for the benefit of patients and the UK economy. Innovative products like this have global potential. That this system has been created and also adopted by BioIndustry Association (BIA) members shows the breadth of our national community and its ability to discover new medicines at a world-class pace and scale”

Chief Executive Officer, BioIndustry Association
Frequently asked questions
Who is Mystra for?
Mystra is used by pharmaceutical and biotech companies - from large global organisations to smaller specialist teams - working on drug target discovery and validation.
Why Mystra?
Building and maintaining the infrastructure for large-scale statistical genetics in-house is a significant undertaking - curating and harmonising data across thousands of studies, keeping pipelines current, and ensuring analyses meet the statistical rigour required for target discovery decisions.
Mystra exists so that drug discovery teams can have immediate access to a comprehensive, analysis-ready genetic data resource and a validated suite of statistical analyses, without the overhead of building or maintaining any of it.
A few things that set Mystra apart:
- Scale and depth of data. Mystra's foundational data resource is built on over a decade of collation and curation by Genomics, combining proprietary meta-analyses - unmatched in scale - with thousands of curated public datasets across GWAS, eQTL, pQTL, and gene burden data types. The data is continuously updated, so your team is always working from the most current evidence base. Genomics also has a growing set of partnerships with private institutions, which enables us to offer additional options to meet particular research needs
- Purpose-built analyses. Every statistical method in Mystra - multi-trait colocalisation, mendelian randomisation, conditional analysis - is implemented and validated specifically for drug target discovery, not adapted from general-purpose tools.
- Ease of use. The Mystra AI co-scientist can orchestrate entire statistical genetics workflows within a single conversation, grounded in real platform data with full traceability. Not a generic chatbot - a genuine accelerant for hypothesis generation and target validation.
- Time to insight. What might take weeks of data wrangling and pipeline work can be done in hours, or even minutes. That speed compounds across a drug discovery programme.
How do I get access to Mystra?
Mystra is fully cloud-based, hosted on AWS - there's no software to install, no on-premise setup, and no IT project to get started. You simply log in through a secure browser with your individual, password-protected account.
Most users work on our shared instance, where onboarding is fast - access can typically be provisioned within hours once commercial and legal agreements are in place. No infrastructure setup is required on your side.
If you're working with large volumes of proprietary data, a dedicated single-tenant instance is also available. The timeline for that depends on scope - we'll walk you through what's involved once we understand your requirements.
Can I run a trial before committing?
Yes. We offer paid 1-3 month trials so that your team can work hands-on with real data before making a longer term subscription decision. The trial structure can be tailored to your organisation's size and use cases - the goal is to make sure you reach a meaningful insight during the trial, not just a surface-level look at the interface. Get in touch to discuss what that would look like for your team.
What analytical tools are available in Mystra?
Mystra brings together exploration tools and statistical analyses in a single platform – no switching between tools or stitching together outputs from different systems.
- Exploration tools let you interrogate the data directly: examine phenome-wide effects for a variant of interest, explore regional association signals across traits at scale, browse gene-based burden test results for rare variants, or run custom lookups via direct SQL access to the underlying database.
- Statistical analyses cover the core methods used in target discovery and validation such as conditional analysis, pairwise and multi-trait colocalisation (using Genomics’ patented MystraColoc algorithm), and Mendelian Randomisation. All analyses run as background jobs and results are fully downloadable.
- Mystra AI acts as an AI co-scientist for statistical genetics – fully embedded in the platform, with access to every tool and dataset. It can orchestrate entire workflows, from submitting jobs to surfacing results, within a single conversation. Every result is traceable back to the underlying data within Mystra.
What data is available in Mystra?
Mystra's data resource is the world’s largest genetic association dataset, which was established a decade ago, and which continues to evolve over time curated by expert statistical geneticists at Genomics. It brings together tens of thousands of GWAS, eQTL, pQTL, and gene burden datasets - including proprietary meta-analyses and curated genetic association data from landmark biobanks (UK Biobank, FinnGen, Million Veteran Program, Genes & Health, All of Us...) and consortia - harmonised into a single, analysis-ready platform.
Coverage spans thousands of unique traits across diverse therapeutic areas spanning the entire phenome. QTL data covers a broad range of tissues and cell types - including blood, brain, liver, and immune cell populations - with both gene and protein-level expression represented.
All data is expert-curated and quality-controlled using proprietary scientific pipelines, aligned to genome build 38, and verified for third-party sharing compliance - so these are not raw summary statistics, but analysis-ready datasets integrated directly into Mystra's workflows.
The foundation data resource is updated fortnightly, and we are also establishing relationships with private institutions to allow us to offer premium data options targeting diverse ancestries, less well-studied disease areas, and deep phenotyping for disease areas of key interest to our partners.
Does Mystra include proprietary data?
Yes. Mystra's foundational data resource combines proprietary datasets and best-in-class meta-analyses - along a broad selection of curated public datasets. All data is harmonised, quality-controlled, and analysis-ready, so you can work across the full catalogue without managing multiple sources or pipelines yourself.
Can I ingest my own data?
Yes. Mystra supports ingestion of proprietary data, making it possible to run analyses against your internal datasets alongside Mystra's foundational data resource. Get in touch to discuss what that would look like for your team.
How is Mystra AI different from generic LLMs?
It is trained on deep knowledge of statistical genetics workflows and full awareness of Mystra's data schema, enabling it to query Mystra's datasets and execute its validated analytical methods in a way no generic LLM can.
Every result is tied to an explicit audit trail: the SQL queries used to retrieve the data, exported intermediate files, analysis IDs, variant identifiers, and workflow IDs. Every step is fully auditable and independently reproducible - directly addressing the reproducibility concerns that have slowed LLM adoption in R&D environments.
Statistical analyses - colocalisation, Mendelian Randomisation, conditional analysis - are all executed by Mystra's dedicated analysis tools, not approximated by the AI.
How does Mystra handle data privacy and security?
Mystra is hosted on AWS, with all data held within Mystra's ultra secure infrastructure. Access is through individual, password-protected accounts, with SSO available for enterprise teams. Genomics holds the highest security certifications in the world, including ISO 27001.
Mystra works exclusively with summary-level association statistics - there is no individual-level genetic data on the platform. All datasets in Mystra's Foundational Data Collection are verified for third-party sharing compliance before inclusion.
When using Mystra AI, your genetic data never leaves Mystra's infrastructure, and your inputs, outputs and proprietary data are never used to train any AI model.
For detailed information on security certifications, data residency, or compliance requirements specific to your organisation, get in touch.

Request your product demo to see how Mystra transforms drug target discovery
Genomics has developed a transformational platform which will change the way diseases and targets are identified for the next generation of drug discovery.
In real time, you can do the work of an entire PhD in minutes.
Chief Medical Officer, Amazon Web Services